An AI engineer is the person who turns model capability into product behavior that real users can depend on. At startups, this is not a research role — it is the job of taking a promising demo and making it survive production: clean data pipelines, reliable deployment, rigorous evaluation, and the product judgment to know when AI is the right tool at all. This guide covers what the role actually involves day to day, the skills startup hiring managers look for, how to build a portfolio that signals real ownership, and how to find and land the right role.
You’re probably seeing the same pattern I see inside startup teams. A product manager asks for an AI feature by next sprint. A backend engineer wires up an API to a model. The demo looks good. Then the hard part starts. The outputs drift, latency spikes, users hit edge cases, and nobody is quite sure who owns the whole system.
That gap is where the ai engineer lives.
In a startup, this role is not a lab job and it is not a pure research role. It is the job of turning model capability into product behavior that users can rely on. That means handling messy data, shaping prompts or model pipelines, deploying services, instrumenting failures, and making trade-offs between speed, cost, quality, and safety.
A lot of people still talk about AI work as if it sits in notebooks. In startups, it sits in customer-facing flows, support queues, recommendation systems, internal copilots, document pipelines, search, and workflow automation. The ai engineer is the person who gets those systems out of the demo phase and into something the company can ship.
An AI engineer is a technical professional who builds, deploys, and maintains systems that use machine learning or foundation models in production. Unlike a data scientist who focuses on experimentation and analysis, or an ML researcher who pushes algorithmic frontiers, an AI engineer is responsible for making AI work reliably inside a real product that real users depend on.
In practice, the role spans four layers. Model integration involves connecting a capable model — whether trained from scratch, fine-tuned, or accessed via API — to a useful product workflow, including prompt design, retrieval pipelines, fallback handling, and output validation. Data pipelines cover the cleaning, ingestion, and normalization work that determines whether a system is reliable before the model ever sees the data. Deployment and infrastructure means packaging the model into a stable, observable service that can handle traffic, recover from failures, and run consistently across environments. Monitoring and iteration closes the loop — tracking output quality over time, catching regressions when prompts or data change, and translating failures into product improvements.
At a startup, an AI engineer often owns all four layers simultaneously. The goal is not the most sophisticated model — it is the most dependable path from user input to useful output, shipped fast enough to matter and stable enough to trust.
A lot of software engineers arrive at this role indirectly. They start by adding an LLM call to an existing product, or by improving an internal workflow with embeddings, classification, or retrieval. Then they realize the true work is not the first prototype. The true work is making that prototype survive production.
That is why the ai engineer role matters so much in startups. Startups do not have the luxury of clean role boundaries. They need people who can move between backend systems, model behavior, product requirements, and operational reliability without getting stuck in theory.
The discipline has deeper roots than the current wave suggests. The field of artificial intelligence was formally established at the 1956 Dartmouth Summer Research Project, where John McCarthy coined the term “artificial intelligence,” a milestone that helped move AI from theory toward organized research and, eventually, modern engineering practice (history of artificial intelligence). That long history matters because it shows a recurring pattern. Hype creates expectations. Progress comes from teams that can validate systems under real constraints.
In a large company, one team can research models, another can own infrastructure, and another can manage product integration. In a startup, one ai engineer may do all three in a week.
That changes the shape of the job:
The rise of accessible model APIs and stronger open source tooling lowered the barrier to building AI features. That did not remove engineering complexity. It moved the complexity.
Instead of asking, “Can we train a model?” startups now ask tougher questions:
A startup usually does not need the most advanced model. It needs the most dependable path from user input to useful output.
The ai engineer sits at that path. That is why the title keeps showing up in high-growth teams. It names the person who turns capability into software, and software into a product that earns trust.
The cleanest way to explain the role is this. If a data scientist designs the blueprint for an intelligent system, the ai engineer builds the bridge, routes traffic across it, and keeps it standing when usage changes.
That means the job is less about isolated modeling skill and more about end-to-end execution.
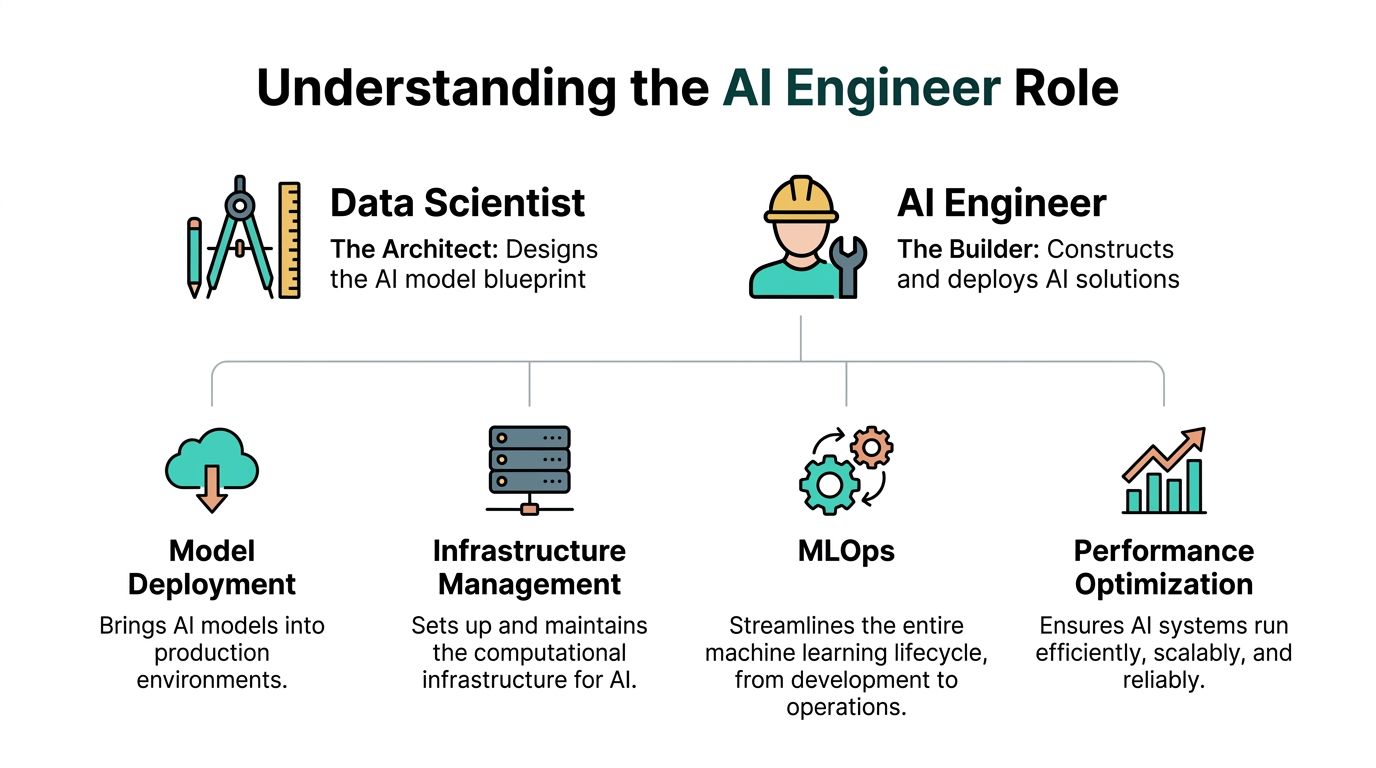
An ai engineer builds, deploys, and maintains systems that use machine learning or foundation models in production. In a startup, “production” has a very specific meaning. Real users depend on it. Real data hits it. Real bugs cost trust.
The work usually spans four layers.
Sometimes the engineer trains a model. Often they adapt an existing one. In many startup stacks, the practical job is connecting a capable model to a useful workflow.
That can mean:
Models can fail without detection when data handling is weak. AI engineers spend a surprising amount of time cleaning source data, reconciling schemas, validating inputs, and building repeatable ingestion jobs.
This is not glamorous work, but it is where reliability starts.
The model is only part of the system. The ai engineer also makes sure the service can run consistently across environments, handle traffic, and recover from failures.
That often involves containers, CI pipelines, cloud services, secrets management, observability, queues, and caching.
A model that works on launch day can still decay in value. User behavior changes. Source data changes. Product requirements change. Prompt changes introduce regressions. An ai engineer tracks those shifts and turns them into an operational loop.
A lot of confusion comes from overlap with data science and research. The distinctions are easier to understand through failure modes.
A data scientist usually focuses on analysis, experimentation, and model exploration. They ask whether the signal exists and which approach is promising.
Their output may be:
A startup needs that work. But a promising notebook is not a shipped system.
A researcher focuses on novel algorithms, architectures, or new model behavior. They push the frontier.
That matters in frontier labs and specialized AI companies. It matters less in most early-stage product teams, where the hardest problem is not inventing a new method. It is making an existing method useful, stable, and economically viable.
The ai engineer asks a different set of questions:
The ai engineer is accountable for usefulness under production constraints, not just technical possibility.
In startup hiring, I look less for someone who can recite framework trivia and more for someone who has built complete loops.
Good signs include:
Weak signals are common too. A repo with five notebooks and no deployment story tells me the person experimented. It does not tell me they can ship.
The ai engineer role exists because AI products break in very ordinary ways. Bad inputs. Thin evaluations. Hidden latency. API fragility. Missing guardrails. A startup needs someone who can see the whole chain and strengthen each link.
A startup ai engineer’s day rarely follows a neat block of “train model in the morning, deploy in the afternoon.” The work is messier and more useful than that. It usually starts with a business problem, not a model choice.
Take a common request. The product team wants a smarter recommendation feature inside the app. Users need relevant suggestions in near real time, and the current rules-based system is too brittle.
The first conversation is not about TensorFlow, PyTorch, or model families. It is about behavior.
You ask:
In startups, this framing step saves weeks. Teams that skip it often build an expensive AI layer for a problem that needed cleaner product logic.
After requirements are clearer, the ai engineer usually audits available data. That means checking event streams, product metadata, user actions, and whatever logging already exists. Most of the time, the first issue is not “we need a smarter model.” It is “our signals are inconsistent.”
Once the target behavior is defined, the next step is preparing data flows that can support training, retrieval, or online inference.
A typical sequence looks like this:
A lot of early AI projects fail here because engineers treat data cleanup as setup work instead of product work. In reality, it is core product work. If the event stream misses key actions, the recommendation system will feel random no matter how good the model is.
By this point, the ai engineer is not just looking at model quality. They are testing the user experience through the service boundary.
That often includes:
This is also where trade-offs become visible. The “best” model in an offline environment may be too slow or too expensive in production. A leaner system with stronger ranking logic and better caching may create a better user experience.
In startups, the winning system is often the one that is easy to debug and iterate, not the one with the fanciest architecture.
After deployment, the work shifts again. You check logs, inspect bad outputs, look for silent failures, and talk to product or support about what users saw.
Three questions matter fast:
Not “is the code running,” but “is the feature doing what we promised?” That requires sampled review, output inspection, and comparison against expected behavior.
Sometimes the system is technically correct and product-wise wrong. Recommendations can be relevant but repetitive. A summarization flow can be fluent but omit the one detail users need. The ai engineer has to notice that gap.
Each iteration should strengthen the system without causing hidden regressions. That means changing one thing at a time when possible, preserving evaluation sets, and writing down failure patterns.
A startup ai engineer spends the day translating between systems and people. Product asks for value. Engineering asks for reliability. The model introduces uncertainty. The job is making all of that cohere into a feature the team can trust enough to keep shipping.
When I review ai engineer candidates for startup roles, I split the signal into two buckets. First, can this person build and operate AI systems in production? Second, can they make good product decisions when the system gets messy?
The strongest candidates have both. The weaker ones usually have only one.
The market talks constantly about frameworks. Startup hiring managers care more about whether you can move from raw data to a monitored service without leaving loose ends.
One skill area keeps separating serious candidates from tutorial-driven ones. Roles requiring MLOps and evaluation expertise grew 40% year over year, and 65% of SF/NYC AI roles list these skills as a key requirement according to the cited analysis in this discussion of AI engineering and evaluation skills.
That aligns with what startup teams need in practice.
Production AI depends on production data discipline. You need to be comfortable with preprocessing, feature engineering, storage, and schema management.
The verified guidance on AI engineering skills is unusually specific here. It points to proficiency with SQL and NoSQL databases, Spark, Hadoop, Pandas, and Matplotlib as part of building production-ready pipelines. It also notes that weak data cleaning can introduce bias and hurt production metrics, with F1-score dropping below 0.85 without effective pipelines, while stronger end-to-end flows can reach 95%+ accuracy in assessment settings, and some high-growth apps generate more than 1TB daily of data (top skills required for an AI engineer).
You do not need all of those tools on day one. You do need the mindset. Pipelines are part of the product.
This is the most under-taught skill in AI hiring.
A startup wants engineers who can answer:
Candidates who can talk about evaluation design stand out fast. Even a simple evaluation harness around classification, extraction, ranking, or LLM output review is more persuasive than a long list of frameworks.
You should know how to package and serve an AI system. That usually means some combination of:
You do not need to run a giant platform team by yourself. You do need to show you can make a model available to a product in a stable way.
Startup ai engineers are expected to do more than implement tickets. They help decide what should be built.
That means you need product sense.
Good candidates can reduce fuzzy requests into tractable decisions. They ask where the AI adds real value, where deterministic code is safer, and where users need transparency.
This matters in every interview loop. Hiring managers want to hear you reason through:
The ai engineer often works across product, backend, design, and support. You need to explain failure modes without hiding behind jargon.
A useful reference point for that broader hiring signal is this Underdog.io piece on what engineering hiring managers look for. The same core pattern holds in AI hiring. Clear thinking is visible in how you describe decisions, not just in the stack you mention.
The same title can mean different things depending on the company.
A startup does not hire an ai engineer to admire the model. It hires them to reduce the distance between an idea and a reliable product behavior.
The hiring signal is simple. Show that you can handle data, evaluate output rigorously, deploy working systems, and make product-minded trade-offs when reality gets inconvenient.
Most ai engineer portfolios fail for one reason. They prove curiosity, not ownership.
A notebook that explores a model is fine. A startup hiring manager wants to know whether you can take responsibility for the whole path from problem to deployed behavior. That is what your portfolio needs to show.
The best portfolio pieces feel like small products.
That means each one should include:
If all you have is model training code, the project is incomplete. Add an API. Add logs. Add tests. Add sample failure cases. Add a basic interface if it helps show the workflow.
Founders and hiring managers skim fast. Make it easy to see the decisions.
A strong project page usually answers five things quickly:
This section is often where a lot of candidates miss the opportunity. They describe the stack but not the reasoning.
You do not need a giant project. You need one that reveals judgment.
Good examples:
Open source contributions can help too, especially if they touch deployment, observability, or evaluation tooling.
Hiring managers use GitHub to infer how you think. That means repository structure, naming, README quality, commit clarity, and issue handling all matter.
This guide on how to make your GitHub more impressive to employers is useful because it focuses on the presentation layer most candidates ignore. Good code hidden inside a confusing repo still loses attention.
If your portfolio requires a hiring manager to guess what is production-ready, they will assume it is not production-ready.
Even when you cannot share confidential company work, you can still write better bullets.
Instead of:
Write:
Instead of:
Write:
Notice the difference. The second version shows ownership.
The goal of a portfolio is not to prove that you know AI terms. It is to make a startup believe you can pick up an ambiguous problem, build something real, and improve it after the first version disappoints everyone a little.
The ai engineer path is broadening, not narrowing. That is the first thing to understand.
In startups, titles are still inconsistent. One company hires an ai engineer to own LLM product features. Another wants someone closer to an ML engineer with strong infrastructure depth. A third expects a full-stack product engineer who happens to be excellent at AI workflows.
At the junior end, the focus is execution. You are implementing services, cleaning data, supporting evaluations, and learning how production systems fail.
At the mid-level, the role becomes more architectural. You are expected to choose patterns, define interfaces, and make trade-offs independently. You can usually own a feature from early framing to deployment.
At the senior and staff levels, the job expands beyond code. You shape platform choices, define evaluation standards, mentor other engineers, and decide when the company should use AI at all.
The title matters less than the scope. In startups, scope changes faster than title updates.
Compensation varies heavily by city, stage, equity structure, and whether the role leans toward infrastructure, product engineering, or applied AI. I am not going to invent salary bands where verified numbers are not available.
One adjacent benchmark is worth knowing. Emerging prompt engineer roles are described as a non-technical entry into AI, and these positions pay a median of $120K+ in US markets according to this overview of non-technical jobs in AI.
That number does not define ai engineer compensation, but it does show something important. The AI job market now includes valuable roles outside the traditional “strong coder with ML background” path.
If you are coming from software engineering, the closest transitions are usually:
If you are coming from a less technical background, prompt engineering and AI content design can be a legitimate bridge. These roles reward writing, logic, experimentation, and structured thinking. They can also teach a discipline many engineers lack. How to define good output.
For people exploring remote options while mapping these paths, a practical reference is this technical career guide for remote engineers. It is not AI-specific, but it is useful for thinking through how infrastructure-heavy roles evolve in remote startup environments.
Do not optimize only for title.
Optimize for:
A surprising number of “AI” jobs are still surface-level integration work with little room to grow. The better roles teach you how data, models, systems, and product judgment interact. That combination compounds much faster than a flashy title.
Startup AI interviews usually reveal a candidate faster than traditional software interviews do. You cannot hide behind memorized buzzwords for long. The team wants to know whether you can ship something useful under imperfect conditions.
Founders and hiring managers usually look for three things.
First, can you explain a project from end to end. Not just the model, but the inputs, service layer, evaluation method, failure cases, and what you would change.
Second, can you reason through trade-offs in real time. If the output quality is good but latency is poor, what do you do? If user trust drops because the AI is inconsistent, what guardrails do you add first?
Third, can you operate in ambiguity. Startup teams often care less about algorithm puzzles and more about how you approach a vague product request.
A few habits consistently improve your odds:
For candidates who want more context on the startup hiring process broadly, this guide on how to get a job at a startup is a useful framing resource.
General job boards make AI hiring noisy. Titles are inconsistent, role scopes are vague, and half the listings lump together research, platform, and product work.
Two filters help.
One is to look for teams that describe the system you would own. Search for mention of evaluation, deployment, APIs, retrieval, monitoring, or product integration. Those clues tell you more than the title does.
The other is to use more targeted channels. If a startup needs specialized help fast, it may work with focused partners such as AI engineer placement services for startups, especially when the role mixes product engineering and applied AI in a way broad recruiters often misread.
If you want a candidate-side option suited to startup hiring, Underdog.io lets you submit one application and get introduced to vetted startups in NYC, SF, and remote US roles when there is mutual fit. That model is useful for AI candidates because startup role definitions vary so much, and direct introductions often surface better matches than keyword-heavy job board searches.
The first startup ai engineer role rarely goes to the person with the most certificates. It usually goes to the person who can prove they understand how an AI system behaves after the demo ends.
An AI engineer builds and maintains software systems that use machine learning or AI models to do something useful in production. In a startup context, that means owning the full path from raw data to a deployed feature: designing or integrating the model or prompt pipeline, building the data infrastructure that feeds it, shipping a service that can handle real traffic and real edge cases, and monitoring quality over time. The role is less about inventing new algorithms and more about making existing model capabilities work reliably inside a product users trust. Day-to-day work includes building inference APIs, writing evaluation harnesses, debugging silent failures, cleaning messy data sources, and collaborating with product and engineering teams to define what "good output" actually means.
The clearest distinction is where responsibility ends. A data scientist typically focuses on analysis, experimentation, and model exploration — they ask whether a signal exists, which approach is most promising, and what the data says. Their output is often an experiment, a prototype, or a recommendation for what should be built. An AI engineer takes that foundation and makes it operational: they build the service, handle the edge cases, instrument the failures, and ensure the system behaves correctly under the conditions real users create. A notebook with strong offline metrics is a data scientist deliverable. A deployed API with evaluation tests, logging, fallback handling, and a plan for iterating on failures is an AI engineer deliverable.
The technical foundation covers several areas. Data handling — SQL, NoSQL, preprocessing, feature engineering, and schema management — is where reliability actually starts, because models can fail without detection when data quality is weak. Evaluation and testing is the most under-taught skill in the field: the ability to define what good output means for a specific task, build representative test sets, and compare model or prompt changes safely. Deployment and serving involves packaging models into Python services, using Docker and cloud infrastructure, managing async queues and caching, and setting up observability. On top of the technical layer, startup AI engineers need product judgment — the ability to frame vague requests into tractable decisions, explain trade-offs to non-technical teams, and recognize when a deterministic solution is safer than an AI one.
AI engineering is one of the highest-compensated specializations in tech. Mid-range salaries for AI engineers average approximately $170,750 in 2026, up 4.1 percent year-over-year — the fastest growth of any engineering specialization tracked. At large tech companies with equity-heavy packages, total compensation for senior AI roles frequently exceeds $300,000. At well-funded startups, base salaries are often slightly lower but equity grants can represent meaningful upside if the company grows. Entry-level or adjacent roles such as prompt engineering positions report median salaries above $120,000 in US markets, illustrating how the entire AI job market has repriced relative to other engineering disciplines.
No. While a PhD can be relevant for research-focused or frontier-model roles, most AI engineering positions at startups — and increasingly at established tech companies — prioritize demonstrated ability to build and operate production systems over academic credentials. Hiring managers at startups consistently look for candidates who can show a complete portfolio project: a deployed service with evaluation logic, error handling, and a clear write-up of the decisions made. That evidence is more persuasive than a degree. A strong background in software engineering, combined with hands-on experience building ML or LLM-powered features and a working knowledge of evaluation and deployment practices, is the practical path most working AI engineers followed.
The titles overlap significantly and are sometimes used interchangeably, but there is a rough distinction in emphasis. An ML engineer traditionally focuses more on the training pipeline side — feature engineering, model training infrastructure, experimentation frameworks, and model serving at scale. An AI engineer, particularly in the context of the current LLM-driven wave, often emphasizes integration work: connecting foundation models or APIs to product workflows, designing prompt pipelines, building retrieval systems, and shipping user-facing features that rely on model output. In practice at a startup, a single person often does both. The more useful question when evaluating a role is not which title it carries but whether the job involves owning a complete system from data to user experience or only one slice of that chain.
A strong AI engineer portfolio demonstrates ownership of complete systems, not isolated model experiments. Each project should include a real problem statement that explains what the system is trying to do and why, an architecture decision that shows the trade-offs considered, a deployed artifact or runnable service that proves the code works outside a notebook, evaluation logic that defines what good output looks like and how changes are tested safely, and a write-up that describes what failed and what changed as a result. Good project types for startup hiring include an AI support assistant with retrieval and fallback handling, a recommendation API with a clean feature pipeline, a document extraction service that returns structured fields and flags uncertain outputs, or an internal tool that automates classification or summarization with explicit quality checks.
The outlook is exceptionally strong. The US Bureau of Labor Statistics projects 34 percent employment growth for data and AI roles from 2024 to 2034 — roughly 82,500 new positions per year — driven by demand across every major industry. Roles requiring MLOps and evaluation expertise have grown 40 percent year-over-year, and the majority of AI roles in major markets now list deployment, evaluation, and production monitoring as key requirements rather than optional skills. The combination of rising demand, limited supply of engineers who can work across the full model-to-product pipeline, and the rapid expansion of AI into core business workflows has positioned AI engineering as one of the most durable high-compensation career paths in technology through at least the end of the decade.
The most reliable path is to build one strong portfolio project that demonstrates end-to-end ownership — a system with real inputs, a deployed service, meaningful evaluation logic, and a clear explanation of the decisions made — rather than a collection of shallow demos. In interviews, being able to walk through that project from problem framing to monitoring, including what broke and how it was fixed, is more persuasive than citing frameworks. Startup interviews specifically test whether candidates can reason through ambiguous product requests and explain trade-offs in non-technical terms. Using targeted channels that specialize in startup hiring, rather than blasting applications across generic job boards where AI role definitions are inconsistent, also meaningfully improves the signal-to-noise ratio of your search.
If you want to explore startup AI roles without blasting your resume across job boards, Underdog.io is a practical place to start. You apply once, your profile is reviewed, and vetted startups can reach out when your background matches what they need. For engineers targeting high-growth teams, that is often a cleaner way to find roles where AI work is tied to real product ownership.



