AI engineer jobs are the fastest-growing category in tech, with LinkedIn ranking "Artificial Intelligence Engineer" as the number one job in the US and unique generative AI job postings growing from 55 in 2021 to nearly 10,000 by mid-2025. But "AI engineer" at a startup is not a research role — it means owning the complete path from messy data to a reliable, deployed product feature. Experienced software engineers are well-positioned for this pivot. The barrier is not learning new frameworks; it is building a portfolio that proves end-to-end ownership, writing a resume that translates existing work into AI-relevant signals, and interviewing with the product judgment startups actually care about.
You’re in one of two spots right now.
You’re a software engineer watching AI features land in every product around you, and you’re trying to decide whether to lean in or stay on your current path. Or you’ve already started tinkering with APIs, embeddings, evals, and agents, but the market for ai engineer jobs still feels fuzzy.
That uncertainty is normal. The title sounds simple; the practice is complex.
At startups, “AI engineer” rarely means “research scientist.” It means someone who can take messy product requirements, turn them into a working system, ship it fast, and keep it alive when users start hammering it. That is good news for experienced software engineers. The people who do well in these roles are strong builders first.
The challenge is not learning one new library. The hard part is learning how startups evaluate AI talent, what they want to see, and how to present your background so hiring managers trust you with a high-impact problem.
AI engineer jobs are roles where you build, deploy, and maintain software systems powered by machine learning or AI models, with direct accountability for how those systems behave in production. At a startup, this is emphatically not a lab or research role. It is product engineering with AI baked into the workflow.
In practice, the responsibilities span the full system: designing or integrating model pipelines (whether LLM-based, retrieval-augmented, or classical ML), building the data infrastructure that feeds them, shipping inference services that handle real traffic and edge cases, and monitoring output quality over time. Startup AI engineers often own all of this simultaneously.
The job market for these roles has grown dramatically. LinkedIn ranked "Artificial Intelligence Engineer" as the number one fastest-growing job in the US, and the share of job postings requiring generative AI skills grew by nearly 10,000 postings between early 2021 and mid-2025. Demand spans three broad role shapes: applied GenAI engineers who build user-facing features with LLMs and RAG; MLOps or platform-leaning AI engineers who own training, inference, and observability infrastructure; and AI infrastructure engineers who optimize serving paths, orchestration, and performance at scale. Most startup roles blend all three.
A lot of engineers approach AI like a total reset. That’s the wrong frame.
If you’ve built APIs, worked with queues, cleaned up bad data, managed cloud deployments, or debugged production failures, you have the foundation for many ai engineer jobs. Startups need people who can make AI systems usable and reliable. They do not need another person who can talk about model benchmarks but freezes when asked how to handle latency spikes, prompt drift, or broken retrieval.

The timing matters. Unique job postings for generative AI skills grew from 55 in January 2021 to nearly 10,000 by May 2025, and LinkedIn ranked “Artificial Intelligence Engineer” as the #1 fastest-growing job category in the U.S. according to Lightcast’s generative AI job market data.
That does not mean every engineer should slap “AI” on a resume and hope for the best. It means the market has created a new layer of product and infrastructure work, and experienced software engineers are well positioned to move into it.
The parts that stay the same are the parts that matter most:
The parts that change are in the stack. You add retrieval pipelines, model selection, eval workflows, prompt iteration, and data quality work. You stop treating intelligence as something you code directly and start treating it as a system you shape, constrain, and monitor.
Most career pivots fail because people optimize for credentials instead of evidence. A course can help you ramp. It will not substitute for proof that you can build.
The fastest path into startup AI work is not “become an expert in everything.” It is “show that you can apply AI to a product problem end to end.”
If you’re changing lanes and want a useful framework for the broader transition, How to Pivot Careers is worth reading because it focuses on reframing existing experience instead of pretending you need to start over.
The strongest candidates I’ve seen make one mental change. They stop asking, “How do I become an AI engineer?” and start asking, “What kind of business problem can I now solve because AI is available?”
That question leads to better projects, better interviews, and better jobs.
“AI engineer” is a blurry title. At a startup, that blur means broad ownership.
One person might build a retrieval pipeline, add caching, wire the model into an app, create offline evals, monitor bad outputs, and sit in on customer calls to hear where the feature breaks. In a larger company, those responsibilities are split across multiple teams.
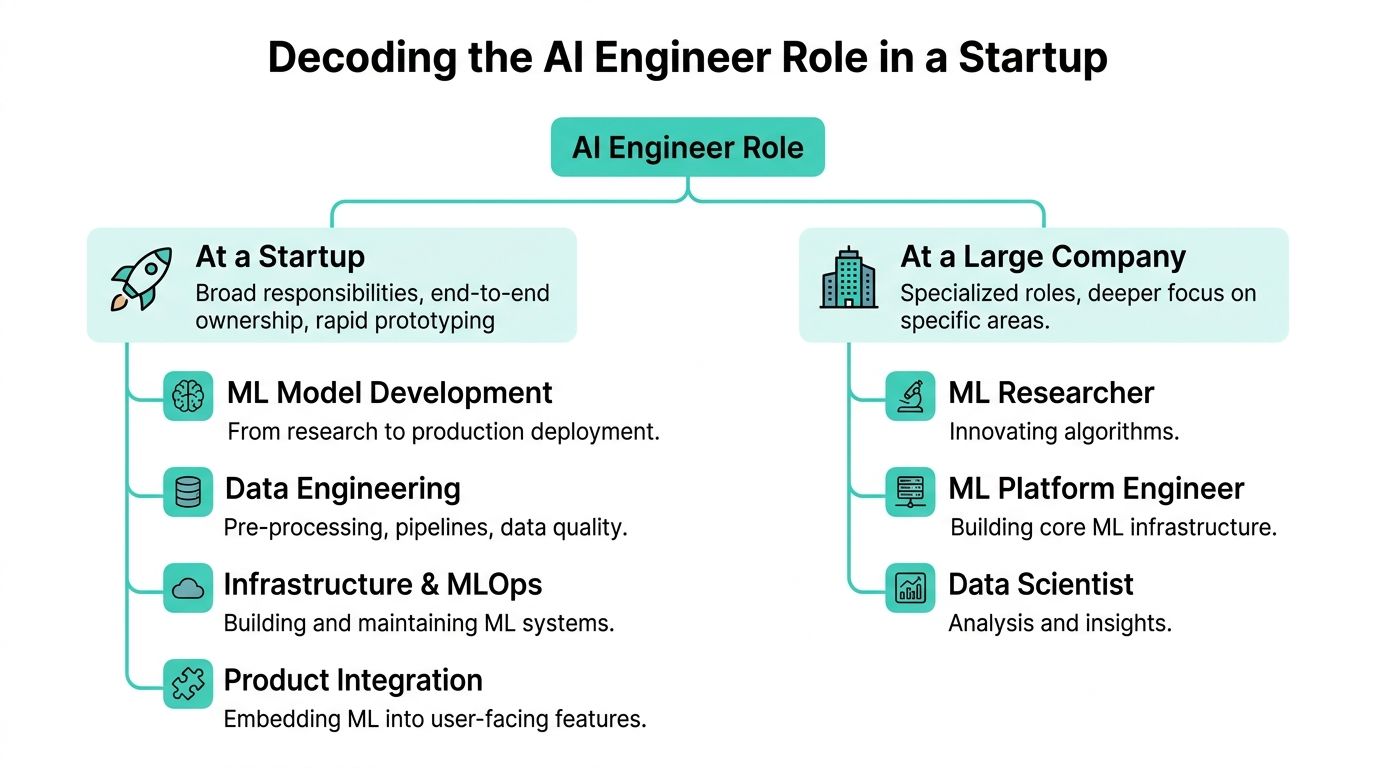
The startup version of the role is less glamorous and more valuable. It is closer to product engineering with machine learning and LLM systems baked into the workflow.
You’ll see three broad shapes.
In practice, early-stage companies want some blend of all three. That’s why candidates with only narrow research experience can struggle. They may understand models thoroughly but lack the habits required to ship a dependable product.
A useful data point frames the gap clearly. Anthropic’s research found that large language models could theoretically handle 94% of programming tasks, but current professional usage covers only 33%, which points to a need for engineers who can close the distance between model capability and production reality, as summarized in this Anthropic discussion reference.
That gap is where startup AI work lives.
The hard problems are rarely “can the model do this in a demo?” They are questions like:
Those are engineering problems. Startups hire for them aggressively.
A good mental model is this: startups want a builder who can own uncertainty.
That includes:
In startup AI work, a decent model inside a disciplined system usually beats a fancy model inside a fragile one.
Some backgrounds look relevant on paper but fall flat in startup interviews.
A few common misses:
The title matters less than the operating model. If the company is small, assume the role includes product, infrastructure, debugging, and customer reality all at once.
That is what makes startup ai engineer jobs hard. It is also what makes them high impact.
A startup does not hire you because you completed a course. It hires you because your work reduces risk.
Your portfolio needs to answer one question quickly: can this person build something useful with AI and get it into production shape?
This matters even more in the current market. A 2025 Stanford Digital Economy Lab study cited by Randstad found a 16% decline in employment for engineers aged 22-25 due to AI automation of entry-level tasks, while 78% of AI/ML roles target candidates with 5+ years of experience in Randstad’s analysis of AI and the engineering talent pipeline. The implication is straightforward. Junior-looking portfolios get filtered out fast. Mature, applied work stands out.
Do not build another toy classifier unless the point is to demonstrate a production system around it.
Better portfolio ideas look like this:
You do not need every tool. You do need a coherent stack.
A good applied foundation often includes:
Most portfolios fail because they show code without judgment.
For each project, include four things.
State the business problem in plain English. Then state the practical constraint.
Maybe latency mattered more than output richness. Maybe the source data was noisy. Maybe users needed citations. Maybe the model hallucinated under sparse retrieval. Hiring managers look for whether you noticed the core problem.
Add a simple architecture diagram. Show the request flow, retrieval path, model layer, storage, and monitoring setup.
This is more persuasive than pages of prose.
Write down what did not work.
Did a bigger model improve output but break cost assumptions. Did aggressive chunking hurt context. Did a pure chat interface confuse users. Did you add a fallback to a search results page when confidence dropped. Those details signal maturity.
A startup-ready portfolio does not present a perfect build. It shows how you handled imperfect conditions.
Use screenshots, a short demo, a deployed endpoint, or a public repo with a clean README. If it is private, write a case-study style breakdown.
A polished README matters more than many engineers want to admit. If your repo is hard to understand, recruiters assume your thinking may be too.
A practical guide on that front is this Underdog post on making your GitHub stand out: https://underdog.io/blog/how-to-make-your-github-more-impressive-to-employers
A few portfolio items weaken your case:
You do not need a fancy personal site. A clean GitHub profile plus a short portfolio page is enough if the content is sharp.
Use this structure:
The point of a startup AI portfolio is not to prove you know AI vocabulary. It is to make a hiring manager think, “This person could join a small team and start building useful things immediately.”
Your resume has two jobs. It has to survive automated screening, and it has to make a human want to interview you.
Those are different problems. Most resumes fail one of them.
The screening problem is now unavoidable. With 87% of companies deploying AI in recruiting and 78% of IT roles requiring AI expertise, your resume needs to communicate applied AI skills clearly enough to pass filters and strong enough to interest a recruiter, as noted in this summary of the AI hiring market.
A lot of software engineers have adjacent experience. They describe it badly.
If you built data pipelines, do not bury that under “backend development.” If you optimized service performance, connect it to inference or high-throughput systems. If you owned observability, mention monitoring and reliability. If you worked on search, ranking, recommendations, or internal tooling, those are all relevant bridges.
Here’s the pattern:
You do not need to exaggerate. You do need to connect your experience to the shape of the role.
For ai engineer jobs, the best resumes front-load these signals:
That means your top third matters a lot. A short summary can help if it is specific. Something like “Backend engineer with experience building production APIs, data pipelines, and LLM-backed workflow tools” works. A vague statement about being “results-driven” does not.
Do include tools and concepts that match your experience: Python, SQL, AWS, GCP, FastAPI, PyTorch, vector search, retrieval, evals, inference, Docker, CI/CD, monitoring.
Do not dump a keyword salad into the bottom of the document. Recruiters see that trick every day. It reads as insecure.
A good test is whether every keyword on the resume can be defended with a project, a role, or a concrete story in an interview.
Weak bullet:
Stronger bullet:
Weak bullet:
Stronger bullet:
Hiring managers scan for ownership verbs. Built, deployed, designed, instrumented, reduced, debugged, evaluated.
For startup roles, a resume alone rarely closes the case. Reviewers jump to your GitHub or portfolio to validate whether the claims are backed by real work.
Your public footprint should make the same argument as the resume. Clean repos. Clear READMEs. Evidence of systems thinking. If you need help tightening the document, this guide is useful: https://underdog.io/blog/how-to-write-a-tech-resume
Complicated templates hurt more than they help.
Use a clean single-column layout. Put skills near the top or just below experience if you are pivoting. Keep dates obvious. Avoid dense paragraphs. Make the first page easy to skim in seconds.
A recruiter should understand three things immediately:
That is enough to earn the next step.
AI engineer interviews at startups are more than software interviews with “LLM” sprinkled on top.
The strongest loops test whether you can build under ambiguity. That means some mix of coding, system design, project deep dive, and product reasoning.

At many startups, this is less about whiteboard trivia and more about whether you can write clean, practical code.
You might still get a standard data structures problem. You may also get something closer to the job:
The mistake candidates make is overfitting on LeetCode and underpreparing for applied coding. You need both. Basic algorithm fluency matters because it signals discipline. But startup interviewers also want to know whether you write maintainable code when the problem looks like real work.
Good software engineers distinguish themselves here.
A common prompt is some variation of: design an AI feature for a product. That could mean a document Q&A system, support copilot, recommendation service, classification workflow, or agent-like automation layer.
A strong answer covers these pieces:
Who is the user. What decision are they trying to make. What level of accuracy is required. Is this an assistive feature or something fully automated.
That framing changes everything.
Where does the input come from. How is it cleaned. How is it stored. How fresh does it need to be. What happens when the source data is wrong.
Do you need a general-purpose hosted model, a smaller specialized model, retrieval, fine-tuning, structured outputs, or a fallback path. Explain why.
Talk about latency, cost, logging, evals, rollback strategy, and abuse prevention. Startups notice when candidates remember that production systems have budgets and on-call implications.
In AI system design, trade-offs matter more than perfect architecture. A candidate who can explain why they chose a simpler, safer design often outperforms someone proposing an overbuilt stack.
This is the highest-signal part of the loop.
Interviewers want to know whether your past work is real, whether your decisions were thoughtful, and whether you understand the difference between a demo and a product.
Use a simple narrative:
That sequence is much stronger than a polished success story. Good interviewers dig for mistakes because mistakes reveal how you think.
Be ready for questions like:
Some startups add a founder or PM conversation that feels less technical. It still matters.
They may ask whether a feature should exist at all. Or what you would ship first. Or how you would respond if users did not trust the outputs.
Many candidates lose points here by sounding like technologists only. Startups want engineers who know that user trust, workflow fit, and iteration speed are part of the technical job.
A solid prep habit is to rehearse the product case for each portfolio project, not solely the implementation details. For broader interview prep discipline, this guide on how to prepare for job interviews is a useful complement because it helps structure practice before the loop starts.
Do not prepare in one mode only.
Mix these:
Candidates who get startup AI offers sound like people who have done the job. Your preparation should aim for that level of specificity.
Getting interviews is one problem. Choosing the right role is another.
A lot of engineers chase the title and ignore the environment. That is how people land in “AI engineer” jobs that are prompt-ops support roles, or backend roles with a thin AI label, or pure experimentation jobs with no product ownership.
Broad job boards are useful for seeing the market. They are noisy for startup discovery.
The more interesting startup openings appear through founder networks, niche communities, specialist recruiters, and curated hiring platforms. That is especially true for narrower roles. Startups are creating niche openings such as “Staff Engineer, AI Agents,” and many of them try to reach the 85% of tech talent that is passively employed and prefers discreet, human-matched introductions, as reflected in this example and market framing from ZipRecruiter.
That fits how experienced engineers move. They rarely spray resumes everywhere. They target a smaller set of roles where their background is unusually relevant.
One option in that mix is Underdog.io, which presents vetted candidate profiles to startups and high-growth tech companies after a short application. For people targeting startup ai engineer jobs, that format can be more useful than a generic application funnel because the company context is already narrowed.
Before you get excited about comp, inspect the shape of the work.
Ask questions like:
The best startup AI roles have clear product pull. Users need the feature. The company has access to relevant data. The team understands that AI systems need iteration, measurement, and engineering discipline. A key factor is understanding the company's commitment to these elements.
Salary matters. It is not the whole offer.
For startup roles, I look at four things first:
A practical reference for the mechanics is this guide on evaluating a startup package: https://underdog.io/blog/how-to-evaluate-a-job-offer
The best negotiation tactic is not theatrics. It is specificity.
If you are talking to a startup, tie your ask to the value you can create. Explain the scope you can own. Reference the mix of product, systems, and AI application work you bring. If the role is broad and impactful, say that directly.
You should also clarify:
Those details matter more than a modest difference in base pay.
The right startup offer gives you room to compound. Better scope on a stronger team beats a slightly prettier title.
The most useful way to think about ai engineer jobs is not as a trend to chase. Think of them as a category of high-responsibility product engineering roles. If you like building, can tolerate ambiguity, and care about shipping systems, this path can be a strong fit.
An AI engineer's daily work at a startup spans several layers simultaneously. It typically starts with problem framing — working with product and engineering to define what a feature should do and what "good output" actually means for that specific use case. From there the work moves into data pipeline work, which involves cleaning source data, reconciling schemas, and building repeatable ingestion jobs that make the system reliable before the model is ever involved. The next layer is integration and testing: writing inference APIs, defining request and response schemas, adding fallback paths, and checking how the feature handles messy real-world inputs. Finally, the role includes monitoring and iteration — inspecting logs, identifying silent failures, and working with product and support teams to understand where the system is and is not creating value for users.
The fastest path is to build one strong, complete portfolio project rather than accumulating certificates or completing many shallow tutorials. The project should demonstrate ownership of the full system: a clear problem statement, a deployed service or runnable artifact, evaluation logic that defines what good output looks like, and a write-up that explains the decisions made and what failed. Good project types include a domain-specific RAG application built on a real document set, an internal copilot for a narrow workflow, or a model-backed feature with human review controls. The goal is not to prove you know AI terminology — it is to make a startup hiring manager believe you could join a small team and start building useful things immediately. Alongside the portfolio, translating any existing software, data, or infrastructure experience into AI-relevant language on your resume closes a significant portion of the perceived gap.
It depends on how you position yourself. The overall demand is extraordinarily strong — job postings for generative AI skills grew from roughly 55 in early 2021 to nearly 10,000 by mid-2025, and the Bureau of Labor Statistics projects 34 percent employment growth for AI and data roles through 2034. However, the market has also become more selective about experience level. A 2025 Stanford Digital Economy Lab study found that 78 percent of AI and ML roles target candidates with five or more years of experience, and entry-level-looking portfolios get filtered out quickly. The opportunity is large but concentrated in candidates who can demonstrate production-level system ownership. Engineers who can show a complete build — deployed, evaluated, monitored — rather than only experimental notebook work are the ones getting interviews.
The technical foundation covers data handling (SQL, data pipelines, preprocessing, and schema management), evaluation and testing (defining quality metrics, building representative test sets, comparing model or prompt changes safely), and deployment and serving (Python services, Docker, cloud infrastructure, API design, observability, and caching). On top of the technical layer, startup AI engineers need product judgment — the ability to reduce vague product requests into tractable decisions, explain trade-offs to non-technical stakeholders, and recognize when a simpler deterministic solution is the better engineering choice. The skill area that most consistently separates strong candidates from tutorial-driven ones is evaluation design, because it is the least commonly taught and the most directly tied to whether AI features earn user trust over time.
AI engineering is among the highest-compensated specializations in software. Mid-range salaries average approximately $170,750 in 2026, up 4.1 percent year-over-year — the fastest salary growth of any tracked engineering specialization. At large tech companies with full equity packages, senior AI engineer total compensation frequently exceeds $300,000 annually. At well-funded startups, base salaries may be modestly lower but equity grants can represent meaningful financial upside if the company grows. The salary premium reflects the scarcity of engineers who can work across the full pipeline from data to deployed product, combined with the direct revenue impact AI features increasingly have on business outcomes.
Yes, and experienced software engineers are often the strongest candidates for startup AI roles precisely because the hardest problems are not model knowledge — they are system reliability, data quality, evaluation rigor, deployment discipline, and the ability to communicate trade-offs clearly. The parts that stay the same are systems thinking, product judgment, execution, and communication. The parts that change are in the stack: you add retrieval pipelines, model selection decisions, prompt iteration, eval workflows, and data quality work as explicit responsibilities. The most effective transition strategy is to build a portfolio project that applies your existing system-building skills to an AI-powered use case, reframe your resume to connect past work to AI-relevant signals, and approach interviews with the same production-mindset that has already served you in software engineering.
The titles overlap significantly and are sometimes interchangeable, but there is a rough practical distinction. Machine learning engineer roles traditionally emphasize the training pipeline side — feature engineering, model training infrastructure, experimentation frameworks, and model serving at scale. AI engineer roles, particularly in the current LLM-driven wave, often emphasize the integration and product side: connecting foundation models or APIs to product workflows, designing prompt pipelines, building retrieval systems, and shipping user-facing features that rely on model output. In startup environments, a single person frequently does both. The more useful question when evaluating a specific role is whether you will own the complete system from data to user experience or only one slice of it, regardless of which title appears in the job posting.
Startup AI engineer interviews typically combine four elements. A coding round assesses whether you can write clean, practical code — not just whiteboard algorithms, but also data wrangling tasks, API design exercises, and small ML-related implementations. A system design round asks you to design an AI-enabled feature from scratch, testing whether you can frame the user problem, define the data path, choose a model strategy, and address operational concerns like latency, cost, logging, and rollback. A project deep dive is the highest-signal stage: interviewers want to know whether your past work is real, whether your decisions were thoughtful, and whether you understand the difference between a demo and a production system — and the strongest answers include a clear account of what failed and what changed. A product judgment round, often with a founder or PM, tests whether you can reason about what to build at all, not just how to build it.
Broad job boards surface the market but generate significant noise because AI role definitions are inconsistent and titles vary widely. The more useful approach for startup discovery is to use targeted channels: curated hiring platforms that vet both companies and candidates, founder and alumni networks, specialist recruiters who focus on AI or technical roles, and niche professional communities where startup operators are active. When evaluating a specific role, look for descriptions that mention system ownership, evaluation, deployment, or product integration rather than vague AI enthusiasm — those signals distinguish roles with genuine engineering depth from ones where "AI engineer" is a marketing label on a standard backend job.
The right choice depends on what you want to optimize for at this stage of your career. A large tech company typically offers a higher, more structured base salary, liquid RSUs, and more defined role boundaries — you may own a specific slice of a large system rather than the whole product. A startup offers broader scope, faster iteration cycles, more proximity to product decisions, and equity upside that can be significant if the company grows, alongside the real risk of company failure and the messiness of systems that are not yet mature. The startup path tends to compound faster in terms of skills and ownership experience, while the large-company path offers more immediate financial certainty. The most useful evaluation question is not "which pays more right now?" but "which gives me the room to build skills and own problems that matter to me for the next several years?"
If you want a quieter way to explore startup roles without spending weeks in application funnels, Underdog.io is built for that. You apply once, your profile is reviewed, and if accepted, vetted startups can reach out about relevant opportunities in NYC, San Francisco, and remote roles across the US.



