You're probably in one of two situations right now. Either you've opened a role for a data scientist and the pipeline is weak, noisy, or wildly misaligned. Or you've already talked to a few candidates and realized everyone means something different when they say “data scientist.”
That's normal in startup hiring. Founders want impact fast. Hiring managers want someone technical enough to model behavior, practical enough to work with messy data, and product-minded enough to influence decisions. Then the search drifts toward a fictional person who can build pipelines, run experiments, productionize models, explain causality to executives, and still move at startup speed.
That search usually stalls because the role definition is wrong before sourcing even starts.
Start with the business problem, not the title. A startup that needs clean pipelines and dashboard reliability usually doesn't need a data scientist first. A startup that already has usable data and wants to improve activation, retention, pricing, or experimentation often does.
The expensive mistake is role inflation. In a tight market, precision matters. McKinsey Global Institute projects that by 2026, demand for data scientists in the United States will exceed supply by over 50%, which means a bad hire profile doesn't just waste time. It slows the company down in a market that's already short on qualified talent, according to this market summary citing McKinsey.
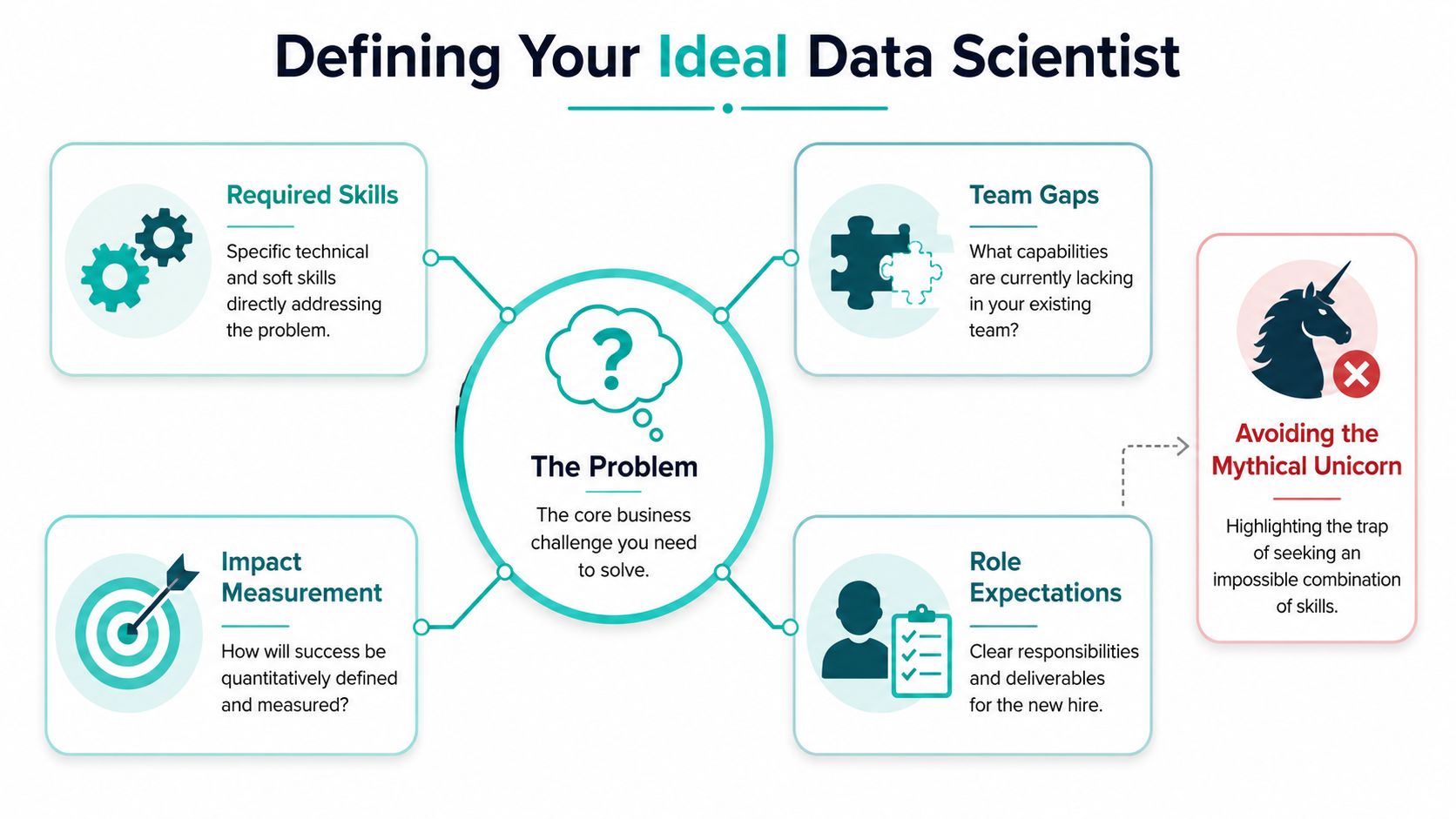
The “unicorn” profile sounds efficient on paper. One hire for analytics, experimentation, forecasting, machine learning, infrastructure, and stakeholder communication. In practice, it creates a vague scorecard, bloated interviews, and a job description that attracts the wrong people.
Use three questions instead.
Are we building infrastructure?
If data is scattered across product logs, Stripe exports, CRM records, and ad platforms, the immediate need may be a data engineer or analytics engineer. A scientist can't do meaningful work if basic tables aren't trustworthy.
Are we optimizing an existing product?
If the team already has events, dashboards, and enough volume to measure behavior, a data scientist can help with A/B testing, churn analysis, funnel diagnosis, and causal reasoning.
Are we exploring a model-driven feature?
If the roadmap includes ranking, recommendations, anomaly detection, fraud checks, or forecasting tied directly to the product, you may need a data scientist with stronger modeling depth and closer partnership with engineering.
Practical rule: Write the problem statement first. Write the title second.
A seed startup usually benefits from someone broad but grounded in analytics. That person should be comfortable with SQL, Python or R, experimentation, and business framing. They need to answer questions like why users drop after onboarding, which segments retain, and whether a product change moved anything meaningful.
A later-stage startup with mature pipelines can justify a more specialized hire. That could be someone stronger in machine learning, causal inference, pricing science, or customer lifecycle modeling.
Here's the simplest working breakdown:
| Role | Best first use case | Common failure mode |
|---|---|---|
| Data Analyst | Reporting, dashboards, business visibility | Gets asked to build predictive systems |
| Data Engineer | Pipelines, modeling layers, data quality | Gets judged on product insights instead of infrastructure reliability |
| Data Scientist | Experiments, predictive analysis, decision support | Gets hired before the company has usable data |
Founders often skip this and pay for it later. If success isn't concrete, every interviewer improvises their own version of the job.
Use a short checklist:
A good startup job description should sound narrower than your fantasy and sharper than your org chart. That's what gets quality signal early.
A founder opens LinkedIn, sends 40 InMails, gets two polite declines, and hears nothing from everyone else. A week later, the role still has no real pipeline, and the team starts debating whether the market is just impossible.
Usually, the problem is the channel mix.
Startups lose time when they borrow sourcing habits from larger companies. Big companies can afford broad top-of-funnel volume, slow follow-up, and a lot of noise in the process. Early-stage teams cannot. The goal is to get to credible conversations fast, with people who are open to startup risk and have done work close to your problem.
The market for data scientists is still tight. The U.S. Bureau of Labor Statistics projects 34% employment growth for data scientists from 2024 to 2034, with about 23,400 openings each year, according to the BLS Occupational Outlook Handbook. For startups, that means cold outreach is competing against a steady stream of recruiter messages, internal referrals, and brand-name companies with more compensation flexibility.
So the sourcing math changes. Passive candidates matter. Warm intros matter. Channels that filter for startup interest matter.
The strongest startup teams I've worked with do not rely on one source. They build a short list of channels that produce different kinds of signal, then they watch which one is generating qualified replies.
A good mix usually includes four lanes:
One more pattern matters here. Companies that share useful thinking before they hire have an easier time getting replies. Good candidates research your team before they engage, especially for startup roles where the risk is higher. If your team is still building that presence, the logic behind a hero channel social media strategy is solid. Pick one channel, show your work consistently, and give candidates something concrete to react to.
Your sourcing brand is what a candidate learns about your team before they answer your message.
Good outreach is short, specific, and tied to a real problem. The candidate should understand why you picked them, what the company needs, and why the role matters now.
Weak message:
“Hey, we're hiring a data scientist at an exciting startup. Open to chatting?”
That gets ignored because it could have been sent to anyone.
Stronger outreach usually includes:
Specificity does two things at once. It improves reply rates, and it repels the wrong candidates early.
For a practical breakdown of how startup teams reach employed candidates without sounding like every other recruiter, this guide to passive candidate sourcing is useful.
Curated marketplaces are useful when the team needs speed and cannot spend weeks sorting weak inbound, chasing cold outbound, and recalibrating the role after every screen. They work best for startups that already know the rough profile they want and need faster access to candidates who are open to startup opportunities.
Underdog.io is one example. It runs as a curated hiring marketplace where candidates complete a short application and startups review pre-screened profiles. That workflow is different from posting on a broad job board and waiting, or asking an internal recruiter to send generic outbound at scale.
There is a trade-off. You get less raw volume than a large public platform. You usually get stronger intent, better startup alignment, and less wasted founder time. For most early-stage teams, that is the better bargain.
A lot of startup interview processes for data roles are still too conversational. Smart people meet a candidate, have an interesting discussion about machine learning, and leave with strong opinions that don't line up. Then the team tries to average gut feelings into a hiring decision.
That's not a process. It's noise.
Unstructured interviews correlate with job performance at only 0.1 to 0.2. Structured processes that include work samples can correlate as high as 0.6. For data scientist hiring, that gap is the difference between collecting real evidence and rewarding whoever interviews well.
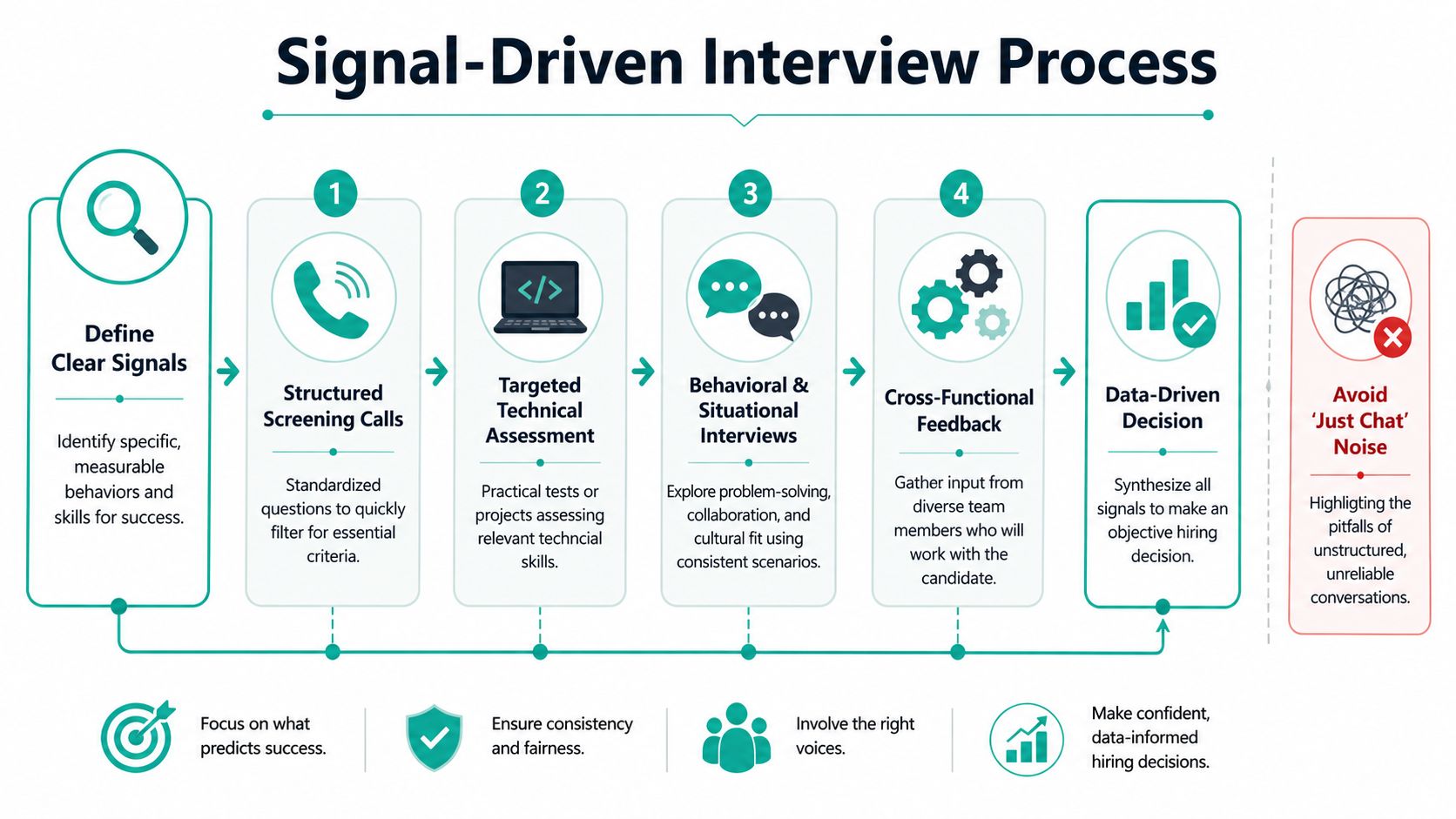
The first conversation should be short and standardized. Not because candidates deserve a robotic experience, but because you need a clean filter.
Use this stage to test three things:
Questions that work well:
Red flags are usually practical, not academic. Vague ownership. No clear decision impact. Inability to explain trade-offs. Talking only about models when the role is mostly product analytics.
The technical interview should feel like problem-solving, not trivia night. Give a senior data scientist, engineer, or analytics lead a structured rubric and ask them to probe fundamentals.
Here's a simple scorecard:
| Signal | What to test | What weak answers sound like |
|---|---|---|
| Data fluency | Handling missing values, outliers, categorical variables | Jumps to tools without defining the data problem |
| Model judgment | Why choose one approach over another | Lists algorithms from memory |
| Experimentation | Treatment and control logic, confounders, causal reasoning | Confuses correlation with impact |
| Communication | Translating findings for non-technical partners | Over-explains mechanics, under-explains decisions |
Use realistic prompts. A consumer startup might ask how the candidate would evaluate a new onboarding flow. A marketplace startup might ask how they'd diagnose a demand-side drop that appears in only certain cohorts. A fintech startup might discuss false positives in a risk model and the business cost of each error.
Hiring note: If your interviewer can't explain what a good answer looks like before the interview starts, the interview shouldn't happen yet.
This last stage should confirm whether the candidate can do the work in a setting that resembles real life. Avoid marathon panel rounds. One practical exercise plus focused discussion is enough.
A strong final stage often includes:
The most useful feedback at this stage isn't “smart” or “not smart.” It's more specific:
Top candidates won't tolerate a process that wanders. Startups should move with intent. Set expectations early, name each step, and tell candidates what each stage is evaluating.
A clean process also reduces bias. Standardized prompts, shared rubrics, and written feedback force interviewers to compare evidence instead of charisma.
Most take-home projects fail for one of two reasons. They're too long, or they're too fake.
Candidates know when they're being handed free consulting work. They also know when the exercise has no connection to the actual job. If you want meaningful signal, the project needs to resemble the role and respect the candidate's time.
The strongest model here is the Data Day approach: a 2 to 3 hour exercise where candidates solve a realistic business problem in a controlled setting. That format works because it tests applied judgment, communication, and technical fundamentals without dragging people through a week of unpaid labor.
A startup version can be simple. Hand over a sample user activity log, some account metadata, and a prompt like: identify three product opportunities, explain the evidence, and note what additional data you'd want before making a decision.
That single exercise can surface a lot:
Teams frequently undermine take-homes through loose evaluation. One interviewer rewards polished notebooks. Another rewards aggressive modeling. Another likes concise writing. That inconsistency turns a good exercise into another subjective round.
Use a pre-written scorecard with a few categories:
| Category | What good looks like |
|---|---|
| Problem framing | Clarifies the business question and states assumptions |
| Technical execution | Clean approach, sensible methods, handles messy data well |
| Insight quality | Recommendations connect to the evidence |
| Communication | Clear narrative, useful visuals or summary, honest limitations |
A take-home shouldn't ask, “Can this person impress us?” It should ask, “Would this person make good decisions with our data?”
Founders often want a “hard” project because they're afraid of making a weak hire. That instinct creates bloated exercises that mostly test stamina and free time.
A shorter, realistic assignment is more predictive. You're hiring for judgment under normal constraints, not endurance under artificial ones.
One more rule matters. Always debrief live. The discussion after the work is often more revealing than the artifact itself. Candidates should walk through what they chose not to do, what assumptions they made, and how they'd validate their conclusions with a product manager or engineer.
Startups rarely win a data scientist on cash alone. That's fine. Strong candidates know the trade. More salary usually comes with narrower scope, slower ownership, and less direct influence over the business.
A startup offer needs to package the upside in a way that feels concrete, not hand-wavy.
Candidates hear “equity” all the time. What they often don't hear is a useful explanation of what they're getting. Founders should walk through the grant in practical terms: how vesting works, what the strike price means, when they can exercise, and what creates upside.
Keep the framing honest. Equity is not guaranteed value. It is ownership with uncertainty attached. Smart candidates respect the company more when that's stated clearly.
A simple script works well:
“We know we won't beat the biggest companies on base salary. What we can offer is broader ownership, direct influence on the product, and a role where your work changes company decisions quickly.”
The strongest startup offers connect the role to a specific future. That usually includes direct access to leadership, messy but meaningful problems, and the chance to build a function early.
Spell it out:
Candidates also want market context. If you're calibrating compensation conversations, this overview of data scientist jobs salary is a useful starting point because it frames salary expectations by role and market reality.
Nothing kills close rates faster than surprise. If approvals are still pending, say so. If equity refresh cadence is unclear, say so. If the company expects broad scope and some ambiguity, say that too.
Good startup candidates don't need a polished fantasy. They need an accurate picture they can opt into with confidence.
The first mistake after data scientist hiring is giving the new person no clean data, no clear partner, and no first win. Then everyone wonders why momentum stalls.
A practical onboarding plan fixes that.
Make access boring and complete. Warehouse credentials, BI tools, dashboards, documentation, event schemas, experiment history, and past strategy docs should be ready before the first morning.
Set one scoped project that matters. Not a vague mandate to “find insights,” but a defined question the business cares about. Give them a go-to partner in product or engineering and a manager who meets weekly.
By this point, the new hire should understand the metrics language of the company and the trustworthiness of the data. This is a good window for a first recommendation memo, experiment readout, or diagnostic analysis with visible stakeholders.
Use regular feedback loops:
A useful reference point here is how strong teams articulate their employee value proposition examples, because retention starts when the role delivered matches the role sold.
Now the focus shifts from onboarding to ownership. The data scientist should be driving a meaningful workstream, not waiting for assignments.
Retention in startups usually comes down to three things: clear impact, credible support, and enough autonomy to do serious work. If those are present early, good people stay.
If you're hiring a data scientist and want a tighter startup pipeline, Underdog.io is built for teams that prefer curated, pre-screened tech candidates over broad inbound volume. It's a practical option when you need faster signal, especially for startup roles where fit and speed matter as much as credentials.


