Reliability engineer salaries in the U.S. usually land in the low to mid six figures, with public datasets putting the average around $115,257 on one end and $155,326 on the other. That spread gets much wider as you move up in scope and seniority, and in practice the difference between a narrowly defined reliability role and a startup infrastructure role can change the offer far more than the title suggests.
You're probably here because an offer is on the table, or you're trying to decide whether your current pay is behind the market. Maybe one company is offering a safer package with a stronger base, and another is offering a lower salary plus equity that could matter a lot if the company executes. The titles look close enough to confuse the comparison. The work often doesn't.
That's the trap with reliability engineer salary research. Most public pages flatten very different jobs into one label. A manufacturing reliability engineer, an infrastructure reliability engineer, and a site reliability engineer can all look similar in a search result, even when the day-to-day work and compensation band are completely different.
The useful way to evaluate your pay is to stop asking, “What does this title pay?” and start asking three narrower questions:
Those answers are what shape negotiation power, especially with startups.
Two offers come in the same week. One is from a public tech company with a clean salary band, formal leveling, and stock that already has a market value. The other is from a Series B startup with a smaller base, a bigger scope, and an options grant that could be meaningful or could be noise depending on the details.
A costly mistake for many engineers is comparing title to title instead of package to package. “Site Reliability Engineer” sounds close to “Reliability Engineer,” so they assume the economics should be close too. They often aren't.
A practical compensation review starts with the work. If a role expects you to own CI/CD, cloud infrastructure, observability, incident response, capacity planning, and production automation, you're usually being hired for a business-critical reliability function. If another role focuses on testing components, process reliability, or a narrower operational remit, it may sit in a different pay lane even when the title overlaps.
Before negotiating, separate the offer into parts:
The last item gets ignored too often. It shouldn't.
Practical rule: If the role carries direct responsibility for availability, incident prevention, and platform automation, negotiate as if the company is buying risk reduction, not just headcount.
That framing matters a lot in startup conversations. Startups may not beat a mature company on cash, but they can sometimes expand scope, title trajectory, and equity in a way that changes the whole package. Big tech can usually offer more structure and predictability. Startups can offer a steeper slope if the company grows and your remit grows with it.
The goal isn't to find one universal number for reliability engineer salary. It's to identify the right peer group, price your actual responsibilities, and negotiate the part of the package that has room to move.
A candidate gets an offer for “Reliability Engineer” at a Series B startup and sees a public average online that looks far lower than the package on the table. Another gets the same title from a large enterprise and assumes the bigger brand means the better deal. Both can misprice the role if they benchmark the title instead of the work, the level, and the company stage.
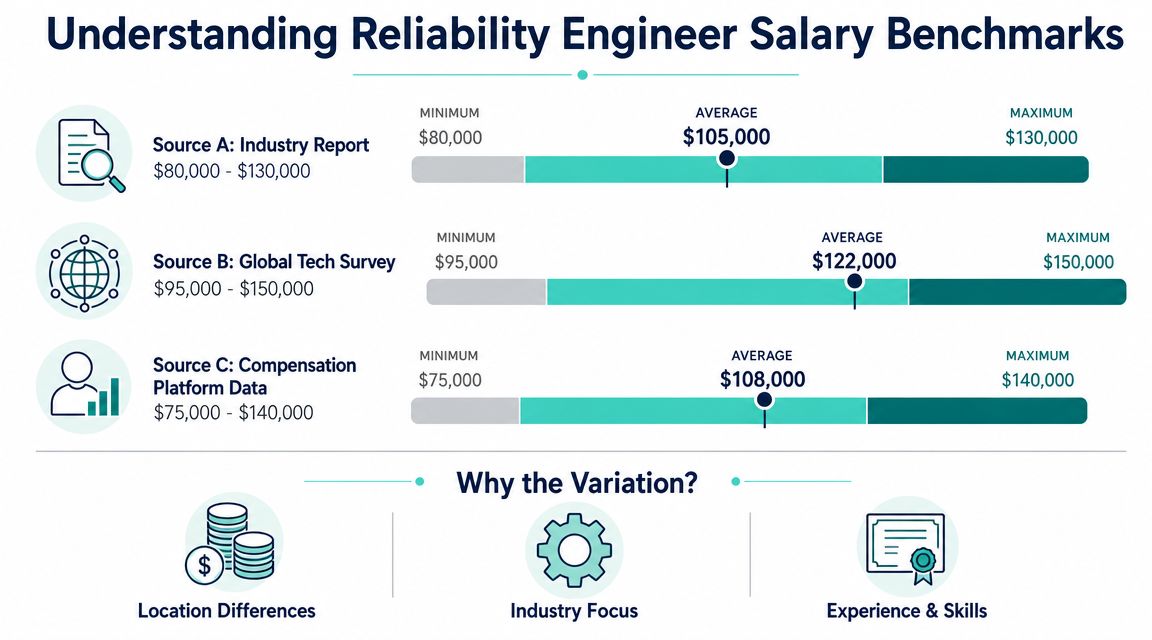
Public salary pages disagree because they measure different populations. Some mix hardware reliability, manufacturing reliability, and production infrastructure roles under one title. Some skew toward self-reported cash compensation. Others publish broader ranges that can include very different levels of seniority.
Indeed's reliability engineer salary page reports an average of $115,257 in the U.S., based on 1.5k salaries from the past 36 months. That number is useful as a reference point, but it should not be your anchor unless the job description matches the kind of roles Indeed is capturing.
The practical move is to treat any public average as a starting marker, not a target number.
The fastest way to misread a market rate is to compare yourself to a blended average. A reliability engineer handling test reliability or component analysis is usually in a different compensation band from an engineer owning production resilience, incident reduction, and platform automation.
That distinction matters even more at startups. Early-stage companies often collapse multiple functions into one hire. If the role includes on-call design, infrastructure automation, incident review leadership, vendor selection, and reliability standards across teams, the market comparison should move up with that scope.
Use salary benchmarks this way:
| What you're reviewing | What to ask |
|---|---|
| Public average | Does this source reflect the same kind of reliability work I'd actually be doing? |
| Salary range | Where should I land based on scope, business impact, and seniority? |
| Level progression | Is the company hiring for this title, or for responsibilities one level higher? |
For nearby market context, compare overlapping infrastructure roles too. Underdog's DevOps engineer salary guide helps if the job mixes platform engineering, automation, and operations work under a different title.
Candidates get more value from benchmarks when they translate them into offer questions. Ask what level this role maps to internally. Ask who owns incident management. Ask whether the position writes production code, owns service-level objectives, or carries recurring on-call responsibility. Those details move compensation more than the title alone.
At a startup, many offers are often misunderstood. Founders may price the role off a narrower “reliability engineer” label while expecting senior SRE-style ownership. If that happens, say it plainly: the package should reflect the operating risk, not just the title on the req.
Base salary still matters. It pays rent and sets your next negotiation floor. But startup offers often shift value into equity, and that only works if the grant is large enough, the strike price is reasonable, the vesting terms are clear, and the company can explain dilution and post-termination exercise terms without hand-waving.
A lower base can make sense. A vague equity story usually does not.
The benchmark that matters is the one tied to your actual scope, seniority, and company stage.
That is the number to bring into the negotiation.
You get an offer for “Reliability Engineer.” The base looks light for the scope, but the recruiter says titles vary by company. Then the hiring manager mentions on-call, incident command, Terraform ownership, service-level objectives, and writing production tooling. That is the moment to stop negotiating against the title and start pricing the actual job.
A lot of salary confusion starts here. Reliability Engineer and Site Reliability Engineer often sit in different compensation bands because they solve different business problems. PayScale's Reliability Engineer salary page shows a much lower average for Reliability Engineer than what many companies pay for SRE work. In practice, the gap usually comes down to scope. SRE work is often tied directly to uptime, customer-facing systems, and the cost of failure.
Titles are loose. Responsibilities are expensive.
When a company expects SRE-level output, the role usually includes several of these:
That mix tends to pay more because the role carries direct operational risk. If the company loses revenue, customers, or trust when systems fail, the person reducing that risk is usually priced closer to platform or backend engineering than to a narrower operations title.
A general reliability engineer role can be very different. It might focus on hardware, manufacturing, test systems, internal process reliability, or support-heavy operational work with limited ownership of core production infrastructure. Those roles can be valuable and still sit in a different salary band.
Candidates miss money when they treat every infrastructure-flavored role as equivalent. The better approach is to audit the req line by line.
Ask these questions:
If the answer is yes to several of those, the company is probably hiring for SRE-grade ownership, even if the title is softer.
For startup candidates, that distinction matters because infrastructure roles are often benchmarked against broader engineering bands. A software engineering salary guide for startup hiring is useful context when the role blends backend, platform, and reliability work.
If a company wants SRE-level ownership under a softer title, negotiate based on the scope they need, not the label they printed.
Early-stage startups often hire for the problem in front of them, not for a polished org chart. One company posts “Reliability Engineer” and really needs the first person who can stabilize infra, build observability, own AWS costs, and run incident response. Another posts “SRE” for a narrower role that mainly maintains alerts and supports deploys.
I tell candidates to test the offer with operating questions, not title questions.
Ask: “What systems would I be accountable for in the first six months?”
Ask: “Who owns the pager today, and what would shift to me?”
Ask: “What reliability goals are already defined, and who is measured against them?”
Those answers tell you where the job sits. They also give you language for negotiation.
If the hiring team describes a role with production ownership, recurring on-call, cross-team incident leadership, and platform automation, say it plainly: “This sounds closer to SRE or platform engineering scope than a narrower reliability title. I'd like the package to reflect that level of ownership.”
That framing works because it is specific. It ties compensation to business risk, execution load, and replacement difficulty. In startup hiring, that is what usually changes the number.
A reliability engineer can hold the same title in two offers and be paid very differently. The gap usually comes from four things: level, scope, technical scarcity, and how expensive failure is for that company.
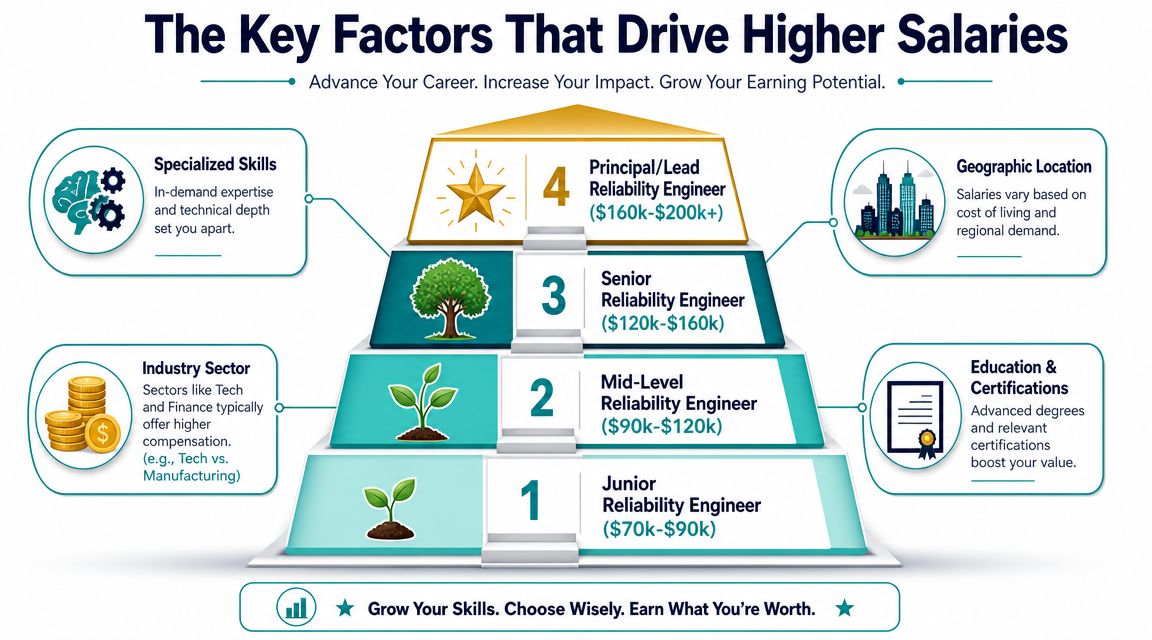
Level is still the cleanest predictor of pay. Senior, staff, and principal compensation rises because the company is paying for judgment, not just output. The role changes from keeping systems running to deciding how reliability should be built across teams.
That distinction matters in negotiation. If you are the person who can reduce incident frequency, set service standards, and influence architecture before production breaks, your market value is closer to platform or senior SRE scope than a narrower support role.
The best salary jumps usually come from a stack of signals, not one impressive keyword on a resume.
I see candidates miss this point all the time. They pitch themselves as a strong generalist when the company is trying to hire someone who can own painful, expensive problems with little supervision.
Use this test before you discuss comp:
| Signal | Lower-value scope | Higher-value scope |
|---|---|---|
| Ownership | Supports one service or team | Owns reliability outcomes across teams |
| Tooling | Operates the current stack | Builds automation, guardrails, and internal platforms |
| Incidents | Responds after paging starts | Leads response and fixes repeat failure patterns |
| Influence | Executes assigned work | Sets standards and shapes architecture |
If the right column describes your work, anchor your compensation discussion to that scope. Do not let the conversation drift back to a generic reliability engineer average.
A simple script works well: “The title is fine, but the scope we've discussed includes cross-team reliability ownership, incident leadership, and platform automation. I'd like the offer calibrated to that level of responsibility.”
Certifications can help. Years of experience can help. A long tools list can help.
They rarely close the gap on their own.
Hiring managers pay more for proof that you changed the reliability profile of a system or a team. That can mean reducing operational toil through automation, building safer deploy paths, cleaning up noisy alerting, improving observability standards, or leading a migration without customer pain. In startup hiring, those examples matter even more because one strong operator can prevent a string of expensive mistakes.
The highest offers usually go to engineers who can handle both sides of the role. They stay calm in production, and they build systems that make future production incidents less frequent, less severe, and cheaper to recover from.
When candidates compare startup and big tech offers, they often compare the wrong line item. They focus on base salary because it's the easiest number to understand. That's reasonable, but incomplete.
A big tech package is usually easier to value. The cash is clearer, the level mapping is tighter, and the equity is often more liquid. A startup package is harder to model because more of the upside sits in assumptions. That doesn't make startup equity bad. It means you need better questions.
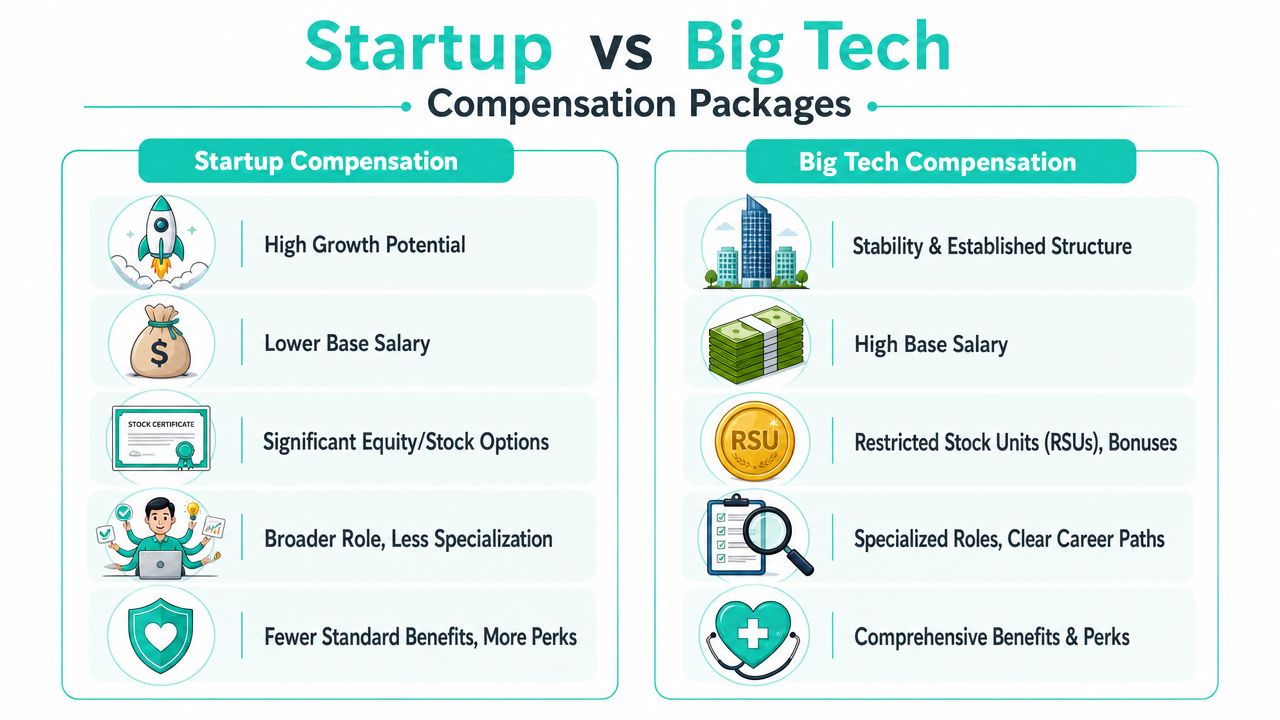
Big tech compensation tends to win on predictability.
You usually get a stronger base, clearer performance cycles, established bonus structures, and equity that has a known market value if the company is public. You also get narrower role boundaries in many cases. That can be good if you want a defined ladder and less ambiguity.
The tradeoff is that you may have less room to expand scope quickly. You might own a smaller slice of the system. Promotions can be slower, and your negotiation room may be constrained by formal comp bands.
Startups usually compete with some mix of broader ownership, faster title growth, and equity. That can be attractive if you're joining a company where reliability is still being built and the team needs someone who can establish core systems, not just maintain them.
The danger is accepting equity on vibes. Don't do that.
Ask for the details that let you understand the grant:
Use this framework when comparing offers:
| Package element | Big tech | Startup |
|---|---|---|
| Cash certainty | High | Lower to mixed |
| Equity clarity | Higher | Lower unless fully disclosed |
| Scope breadth | Often narrower | Often broader |
| Career path | More formal | More flexible, less predictable |
| Risk | Lower | Higher |
Personal context matters. If you need dependable cash because of mortgage, family, or visa constraints, a lower startup base may be the wrong kind of risk. If you're earlier in your career, can absorb uncertainty, and want broad platform ownership, a startup can make sense even with a smaller salary if the equity is real and the scope is unusually strong.
One more practical point. A startup with weak fundraising discipline can create compensation problems later. If you want to understand how companies manage capital planning and investor process, a tool like Gritt's startup fundraising workflow tool is useful context because it shows the operational side behind the financing story you're being asked to bet on.
Startup negotiation goes better when you treat it as a problem-solving conversation, not a showdown. Most founders and hiring managers expect some discussion. What they don't want is a vague demand disconnected from the role.
The strongest counteroffers anchor on scope, market fit, and commitment.
If the base is below where you need it, keep the framing calm and specific:
“I'm excited about the role and the scope. Based on the production ownership, on-call expectations, and infrastructure work involved, I was expecting a package with a higher cash component. Is there room to move the base salary upward while keeping the rest of the offer structure intact?”
That works because it ties your ask to the actual job, not to a random number you found online.
If they say the salary band is tight, don't stop there. Ask what can move besides base.
A lot of startups have more flexibility on equity than cash. If that's the case, use it directly:
“If the base salary is fixed, I'd like to talk about increasing the equity portion. I'm comfortable taking startup risk when the grant reflects the level of ownership you're asking for.”
That line is effective because it tells them you understand the trade. You're not rejecting startup economics. You're pricing them properly.
Ask these before you accept:
If a company won't answer reasonable equity questions, treat that as signal.
For a deeper walkthrough of option mechanics, tax implications, and the questions candidates usually forget to ask, Underdog's guide on how to negotiate stock options is a solid companion to this conversation.
Three negotiation mistakes show up all the time:
A good fallback line is simple:
“If we can't close the gap fully on day one, I'd like to define what results would support a compensation review after I've had time to deliver.”
That keeps the relationship constructive and gives you a second shot on a timeline.
You get the strongest outcome when you benchmark the actual job, not the title on the offer letter. A reliability engineer who owns incident response, Kubernetes, and service-level objectives at a Series A startup is in a different pay band from someone with the same title handling ticket-driven ops work at a larger company. That distinction matters more than the label.
Use outside sources for different jobs. Levels.fyi is useful for comparing established tech-company pay bands and leveling. Holloway's equity guide helps candidates check whether an options grant is meaningful or just hard to evaluate. If you are assessing startup health alongside compensation, a startup fundraising workflow tool can also help you understand how organized a company is around financing and planning.
One practical habit helps here. Build a simple comparison doc for each offer with five lines only: base salary, bonus, equity details, scope, and review timing. That format exposes weak offers fast. It also keeps you from overweighting brand name or title prestige when the fundamental trade-off is cash today versus upside later.
Stay disciplined with your filters. Compare startup roles to startup roles. Compare infrastructure ownership to infrastructure ownership. If you cannot explain the equity in plain English, pause the process and get answers before you sign.
Your next offer should match your risk tolerance, your operating strengths, and the kind of systems you want to own.
If you're exploring startup engineering roles and want a more focused pipeline than a general job board, apply through Underdog.io to get matched with vetted startups that are actively hiring.



